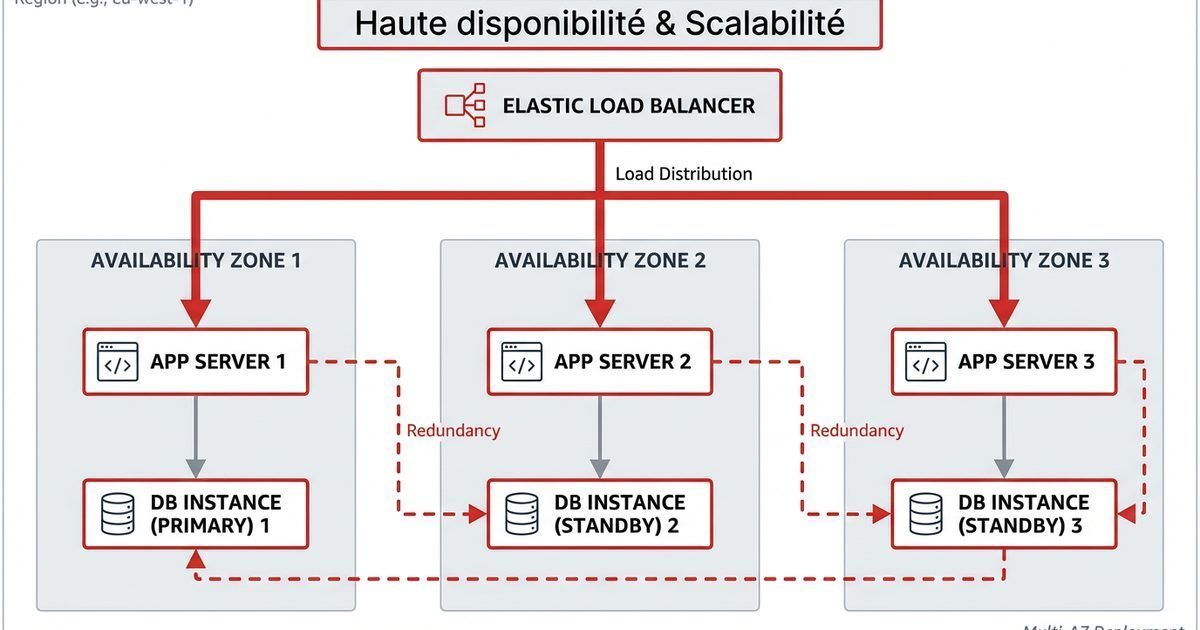
Architectures AWS : haute disponibilité et scalabilité
AWS brille quand il s’agit de tenir la charge et de survivre aux pannes matérielles. Encore faut‑il structurer ton architecture pour en profiter.
1. Les briques de la haute disponibilité
1.1 Multi‑AZ
Beaucoup de services AWS peuvent être déployés en Multi‑AZ :
- RDS / Aurora ;
- ALB (load balancers) ;
- Auto Scaling Groups d’EC2 ;
- EKS, ECS (avec des nodes répartis).
L’idée : si une AZ tombe, une autre prend le relais.
1.2 Load balancing
- ALB distribue le trafic HTTP/HTTPS vers plusieurs instances/containers.
- Tu peux définir des règles :
- par path (
/api/,/admin/) ; - par host (
api.,admin.).
2. Patterns d’architecture web courants
2.1 Appli web classique robuste
- Route 53 + CloudFront (optionnel) → ALB en Multi‑AZ ;
- Auto Scaling Group d’EC2 ou ECS/Fargate derrière l’ALB ;
- RDS/Aurora en Multi‑AZ.
Caractéristiques :
- plusieurs instances applicatives ;
- base de données répliquée ;
- tolérance à la perte d’une AZ.
2.2 Architecture serverless
- Route 53 + CloudFront → API Gateway ;
- Lambdas derrière API Gateway ;
- DynamoDB / Aurora Serverless / S3.
Avantages :
- pas de serveurs à gérer ;
- scalabilité quasi automatique ;
- facturation à l’usage.
3. Autoscaling : adapter la capacité à la charge
3.1 Auto Scaling Groups (EC2)
- Tu définis un min / max / desired capacity ;
- des politiques d’auto‑scaling réagissent à :
- la charge CPU ;
- la taille d’une queue (SQS, Kafka) ;
- des métriques custom (latence, erreurs).
3.2 ECS / EKS / Lambda
- ECS/EKS : scaling en nombre de tâches/pods, couplé à des métriques (CPU, mémoire, backlog).
- Lambda : scaling géré par AWS, mais tu peux ajuster la concurrency et les quotas.
4. Tolérance aux pannes
4.1 Niveaux de pannes
- Panne d’instance → couverte par l’auto‑scaling / health checks.
- Panne d’AZ → couverte par le Multi‑AZ (LB, bases, nodes répartis).
- Panne régionale → besoin de multi‑région, plus complexe (réplication des données, routage DNS).
4.2 Bonnes pratiques
- Ne jamais dépendre d’une seule instance pour un composant critique.
- Avoir des backups testés et une procédure de restauration documentée.
- Tester des scénarios de panne (game days, chaos engineering light).
5. Gouvernance et coûts
Plus tu ajoutes de redondance, plus le coût grimpe. Il faut donc :
- choisir le bon niveau de disponibilité selon la criticité (SLA interne) ;
- ne pas sur‑dimensionner les environnements non‑prod ;
- utiliser les Savings Plans / Reserved Instances pour les charges stables.
6. Résumé
Construire une architecture AWS haute dispo et scalable, c’est :
- répartir les ressources sur plusieurs AZ ;
- utiliser des load balancers et l’auto‑scaling ;
- choisir les bons services managés (RDS/Aurora, ECS/EKS, Lambda, S3).
Le tout piloté par une observabilité solide et une gestion attentive des coûts, abordées dans les articles voisins de cette série.+