Bases de données AWS : RDS, DynamoDB, Aurora – laquelle choisir ?
Une architecture AWS solide repose sur des bases de données bien choisies. AWS propose beaucoup d’options (RDS, DynamoDB, Aurora, document DB, time series, etc.). Ici, on se concentre sur les trois piliers les plus courants pour les applications web et SaaS.
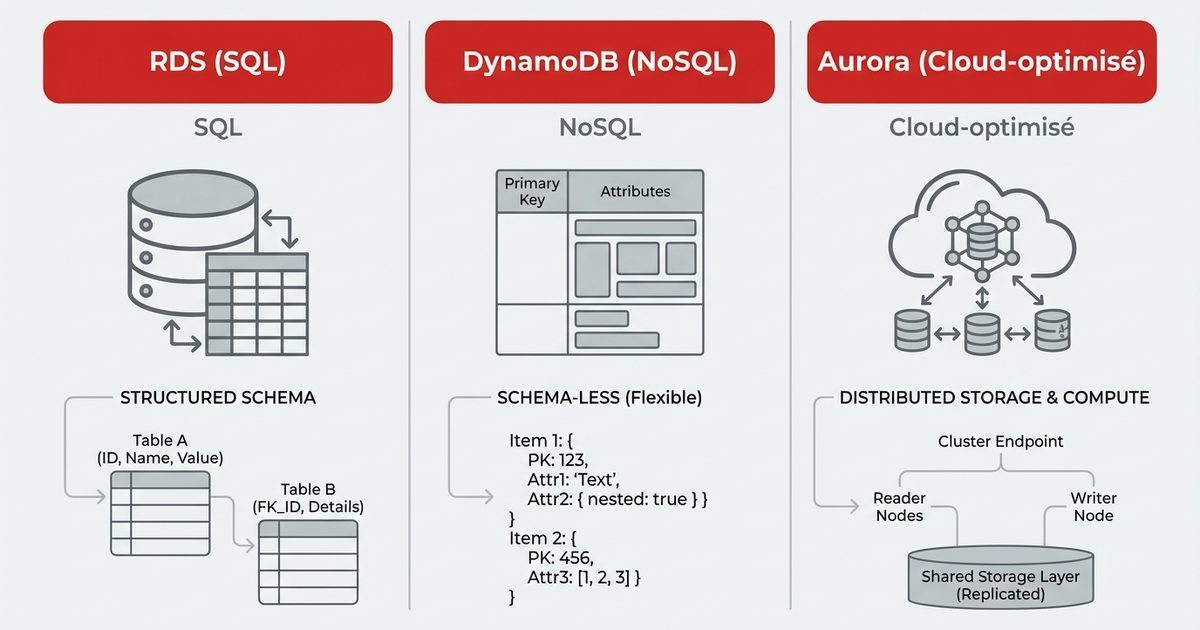
1. RDS : bases relationnelles managées
1.1 Modèle
RDS (Relational Database Service) te fournit des bases relationnelles gérées :
- moteurs supportés : PostgreSQL, MySQL, MariaDB, SQL Server, Oracle, Aurora… ;
- AWS gère :
- les backups automatiques ;
- les mises à jour mineures ;
- la haute disponibilité (Multi‑AZ) si tu l’actives.
Tu gardes la main sur :
- le schéma, les index, les requêtes ;
- la taille de l’instance et le tuning SQL.
1.2 Cas d’usage
- APIs / backends classiques (SaaS, e‑commerce, ERP, CRM).
- Applications qui utilisent déjà un ORM ou du SQL classique.
1.3 Optimisation
- Activer le Multi‑AZ pour les environnements critiques.
- Surveiller les métriques clés :
- CPU, IOPS, latence disque ;
- connexions actives ;
- temps de réponse des requêtes.
- Indexer correctement les colonnes filtrées/jointes.
2. DynamoDB : NoSQL clé/valeur ultra scalable
2.1 Modèle
DynamoDB est une base NoSQL clé/valeur (et document) entièrement managée.
- Pas de serveur à gérer, pas de capacité fixe à prévoir (en mode on‑demand).
- Latences très faibles, même à grande échelle.
- Modèle de données basé sur :
- une clé de partition (et éventuellement de tri) ;
- des index secondaires pour d’autres patterns d’accès.
2.2 Cas d’usage
- Applications avec fort trafic et patterns d’accès bien définis.
- Tables d’authentification, sessions, paniers, events, logs haute fréquence.
- Systèmes temps réel et IoT.
2.3 Optimisation
- Concevoir le schéma à partir des requêtes (on ne “découvre” pas la structure après coup).
- Utiliser le mode on‑demand pour commencer, puis provisionned si les volumes sont stables.
- S’assurer que la clé de partition répartit bien la charge (éviter les “hot partitions”).
3. Aurora : base relationnelle optimisée pour le cloud
3.1 Modèle
Amazon Aurora est une base relationnelle compatible MySQL/PostgreSQL, mais re‑architecturée pour le cloud :
- stockage distribué, séparé du compute ;
- réplication automatique sur plusieurs AZ ;
- restauration rapide à n’importe quel point dans le temps.
3.2 Cas d’usage
- SaaS à fort trafic qui dépasse les capacités des RDS classiques.
- Besoin de haute disponibilité et de réplication rapide en lecture.
3.3 Optimisation
- Utiliser les réplicas en lecture pour absorber les requêtes de reporting.
- Surveiller la taille du cluster, la charge en lecture/écriture, les buffers.
- Envisager Aurora Serverless v2 pour les charges très variables.
4. Comment choisir entre RDS, DynamoDB et Aurora ?
Quelques règles simples :
-
Tu as une appli web classique avec SQL, relations, jointures
→ commence par RDS (PostgreSQL). -
Tu as des besoins de scalabilité extrême sur des patterns simples, type clé/valeur ou time‑series
→ regarde DynamoDB. -
Tu as déjà une base relationnelle qui commence à souffrir et tu as besoin d’un palier supérieur en termes de disponibilité et de performance
→ évalue Aurora.
Combinaisons fréquentes :
- RDS pour le cœur métier + DynamoDB pour des caches et événements.
- Aurora pour les données critiques + S3 pour l’archivage long terme.
5. Gestion, sécurité et gouvernance
5.1 Sécurité
- Toujours restreindre l’accès réseau (VPC, security groups, pas d’accès public direct si possible).
- IAM minimal pour les applications (un rôle par service).
- Chiffrement au repos activé (RDS, DynamoDB, Aurora + KMS).
5.2 Sauvegardes et reprises
- Vérifier régulièrement les politiques de backup (réten tion, restauration testée).
- Documenter des scénarios de reprise (perte AZ, déploiement raté, corruption applicative).
5.3 Coûts
- Surveiller la taille des bases et les I/O.
- Nettoyer les environnements de test/démo obsolètes.
- Adapter le gabarit des instances / throughput DynamoDB à l’usage réel.
6. Résumé
Sur AWS, la base “par défaut” reste souvent une relationnelle (RDS/Aurora), mais tu as tout intérêt à :
- bien poser ton modèle de données et tes pattern d’accès ;
- utiliser DynamoDB quand tu as un besoin clair de NoSQL scalable ;
- combiner S3, RDS/Aurora et DynamoDB pour couvrir archivage, transactionnel et temps réel.
Dans le prochain article, on descendra d’un niveau pour parler réseau (VPC, subnets, sécurité, Route 53, CloudFront) et voir comment connecter proprement tous ces services.+