JobHunter
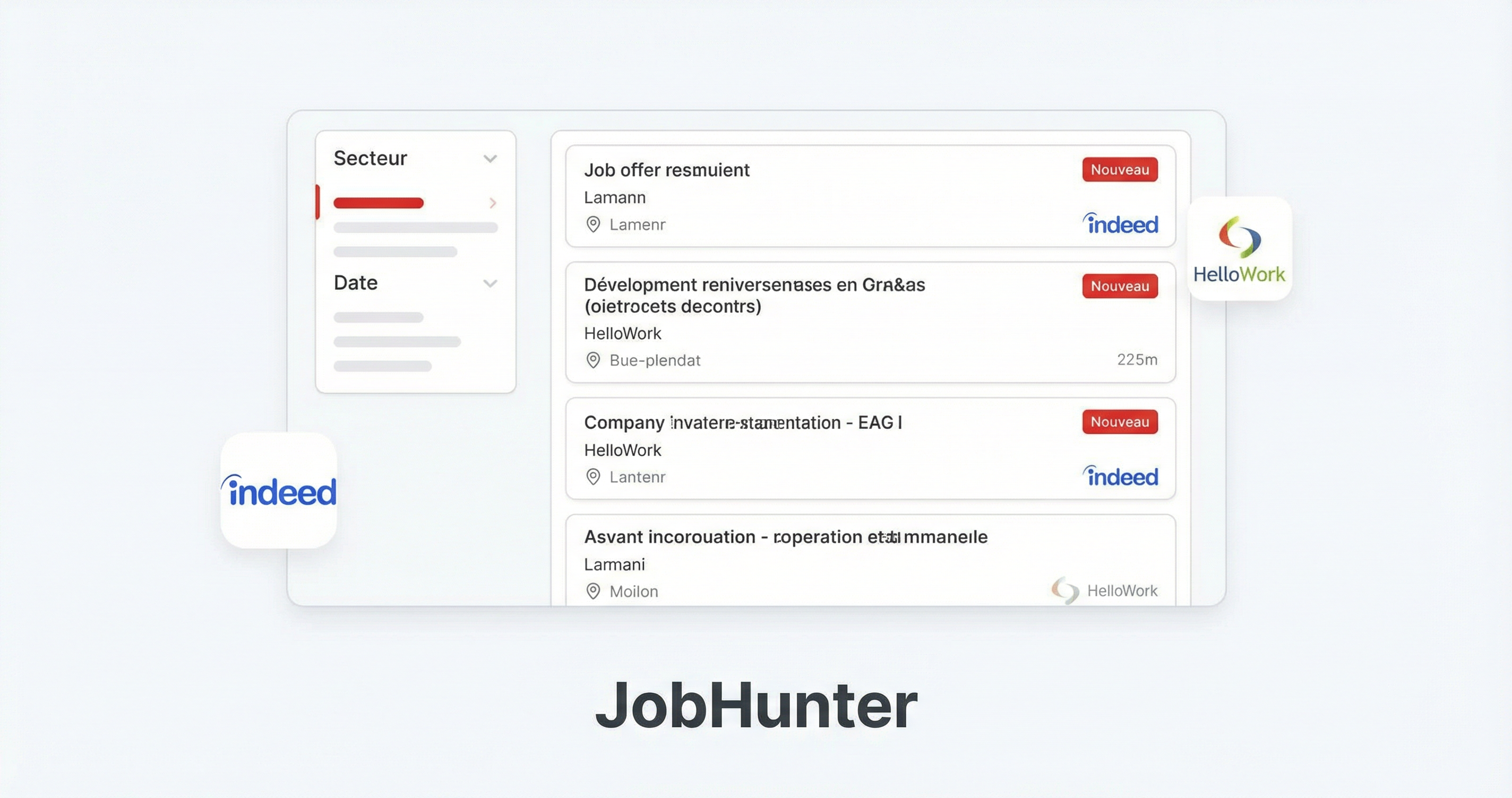
Systeme de scrapping intelligent d'offres d'emploi et d'interim (Indeed, HelloWork, LinkedIn, France Travail, Actual). API FastAPI, Celery, optimise Raspberry Pi.
Technologies
Documentation du projet
JobHunter 🎯
Système de scrapping intelligent d'offres d'emploi et d'intérim, optimisé pour Raspberry Pi 3B+ avec Python 3.9.
🚀 Fonctionnalités
- Scraping multi-sites : Indeed, HelloWork, LinkedIn, France Travail, Actual
- Déduplication intelligente : Algorithme de similarité fuzzy
- API REST complète : FastAPI avec documentation automatique
- Tâches asynchrones : Celery pour le traitement en arrière-plan
- Monitoring avancé : Métriques système et métier
- Optimisé RPi : Configuration adaptée aux ressources limitées
🏗️ Architecture
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Frontend │ │ API REST │ │ Scrapers │
│ (React) │◄──►│ (FastAPI) │◄──►│ (Python) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│
▼
┌─────────────────┐
│ PostgreSQL │
│ + Redis │
└─────────────────┘
📋 Prérequis
- Système : Raspberry Pi OS (64-bit recommandé)
- Python : 3.9 ou supérieur
- RAM : 2GB minimum (4GB recommandé)
- Stockage : 8GB minimum (16GB recommandé)
- Services : PostgreSQL 12+, Redis 6+
🛠️ Installation rapide
Linux/macOS
Option 1: Avec Conda (recommandé)
# Cloner le projet
git clone <repositoryurl>
cd jobhunter
Installation complète avec conda
./scripts/condainstall.sh
Démarrer l'application
./scripts/condastart.sh
Option 2: Avec venv
# Cloner le projet
git clone <repositoryurl>
cd jobhunter
Installation avec venv
./scripts/install.sh
Démarrer l'application
./scripts/start.sh
Windows
Option 1: Avec Conda (recommandé)
# Cloner le projet
git clone <repositoryurl>
cd jobhunter
Installation complète avec conda
scripts\condainstallwindows.bat
Démarrer l'application
scripts\condastartwindows.bat
Option 2: Avec venv
# Cloner le projet
git clone <repositoryurl>
cd jobhunter
Installation avec venv
scripts\installwindows.bat
Démarrer l'application
scripts\startwindows.bat
Configuration
# Copier et éditer la configuration
cp env.example .env
Éditer .env avec vos paramètres
L'API sera disponible sur http://localhost:8000
🚀 Démarrage rapide
Scraping d'offres
# Via l'API
curl -X POST "http://localhost:8000/api/v1/scraping/start" \
-H "Content-Type: application/json" \
-d '{
"searchterms": ["développeur python", "data scientist"],
"location": "Paris",
"maxpages": 5
}'
Recherche d'offres
# Lister les offres
curl "http://localhost:8000/api/v1/jobs?search=développeur&location=Paris&limit=10"
Statistiques
curl "http://localhost:8000/api/v1/jobs/stats"
Monitoring
# Santé de l'API
curl "http://localhost:8000/api/v1/health/detailed"
Métriques système
curl "http://localhost:8000/api/v1/monitoring/metrics"
📚 Documentation
- Architecture - Vue d'ensemble du système
- Installation - Guide d'installation détaillé
- API - Documentation complète de l'API
- Scraping - Guide du système de scraping
🔧 Configuration
Variables d'environnement principales
# Base de données
DATABASEURL=postgresql://jobhunter:password@localhost:5432/jobhunter
REDISURL=redis://localhost:6379/0
API
APIHOST=0.0.0.0
APIPORT=8000
APIWORKERS=2
Scraping
SCRAPINGDELAYMIN=1
SCRAPINGDELAYMAX=3
SCRAPINGCONCURRENTREQUESTS=2
Optimisations RPi
RPIMODE=true
LOWMEMORYMODE=true
MAXWORKERS=2
🎯 Sites supportés
| Site | Type | Filtres | |------|------|---------| | Indeed | Emploi généraliste | Localisation, contrat, expérience, salaire | | HelloWork | Emploi français | Localisation, distance, contrat, expérience | | LinkedIn | Réseau professionnel | Localisation, temporel, contrat, expérience | | France Travail | Service public | Localisation, rayon, contrat, expérience | | Actual | Intérim | Localisation, rayon, contrat, expérience |
🔄 Tâches programmées
- 6h : Scraping quotidien général
- 8h : Scraping intérim
- 2h : Nettoyage des données
- 3h : Déduplication des offres
📊 Monitoring
Métriques système
- CPU, mémoire, disque
- Alertes automatiques
- Logs structurés
Métriques métier
- Nombre d'offres scrapées
- Taux de déduplication
- Qualité des données
🚨 Dépannage
Problèmes courants
sudo systemctl status postgresql
# Activer le mode basse mémoire
echo "LOWMEMORYMODE=true" >> .env
# Augmenter les délais
echo "SCRAPINGDELAYMIN=2" >> .env
echo "SCRAPINGDELAYMAX=5" >> .env
Logs
# Logs de l'application
tail -f logs/jobhunter.log
Logs de scraping
tail -f logs/scraping.log
Logs d'erreurs
tail -f logs/errors.log
🔧 Développement
Structure du projet
jobhunter/
├── app/
│ ├── api/ # API REST FastAPI
│ ├── core/ # Configuration et utilitaires
│ ├── models/ # Modèles de données
│ ├── scrapers/ # Scrapers pour chaque site
│ ├── services/ # Services métier
│ └── tasks/ # Tâches Celery
├── docs/ # Documentation
├── logs/ # Fichiers de logs
└── tests/ # Tests unitaires
Ajout d'un nouveau scraper
BaseScraperscrapejobs() et parsejoboffer()ScrapingManagerTests
# Tests unitaires
pytest tests/
Tests avec couverture
pytest --cov=app tests/
📈 Performance
Optimisations RPi
- Pool de connexions limité
- Workers Celery réduits
- Délais de scraping adaptatifs
- Monitoring des ressources
Recommandations
- Utiliser un SSD pour de meilleures performances
- Surveiller la température du RPi
- Configurer des alertes de ressources
🤝 Contribution
📄 Licence
Ce projet est sous licence MIT. Voir le fichier LICENSE pour plus de détails.
🆘 Support
- Documentation : docs/
- Issues : GitHub Issues
- Discussions : GitHub Discussions
🎉 Remerciements
- FastAPI pour l'API
- Celery pour les tâches asynchrones
- Scrapy pour l'inspiration du scraping
- PostgreSQL pour la base de données
JobHunter - Scraping intelligent d'offres d'emploi pour Raspberry Pi 🎯
Projets suggeres
CvLetterAssistant
Demo lettre de motivation et tips CV avec LLM local (Ollama), Express
OutilsDispyCluster
Cluster de calcul distribue Raspberry Pi - scraping, monitoring, API, Dispy
OutilsYoutubeDownloader
Plateforme telechargement videos YouTube, Dailymotion - Python AngularJS
OutilsDispyCluster
Système de clustering distribué pour le traitement de données.